





| Главная » Статьи » Железо |
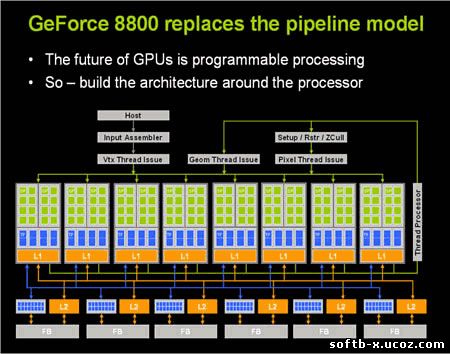
ПредисловиеПоявление видеокарт на основе графических процессоров NVIDIA G80 и ATI R600 обозначило начало нового этапа развития индустрии компьютерных игр: появилась поддержка нового интерфейса прикладного программирования (API, Application Programming Interface) от Microsoft — DirectX 10. Ключевым условием поддержки DirectX 10 является унифицированная шейдерная архитектура графического процессора. Первой видеокартой, соответствовавшей данному требованию, была GeForce 8800 GTX на основе графического процессора G80 с его 128-ю унифицированными шейдерными конвейерами. Ответом компании ATI стал продукт под названием Radeon HD 2900 XT на основе графического процессора R600, обладающего 320-ю шейдерными конвейерами. Исходя из характеристик вышеупомянутых видеокарт, несложно определить их теоретическую пиковую шейдерную производительность. Шейдерная подсистема R600 работает с той же тактовой частотой, что и остальная логика (740 МГц), в то время как у G80 частота этой подсистемы значительно выше (1,35 ГГц). Теоретическая пиковая шейдерная производительность Radeon HD 2900 XT равна 236,8 млрд. условных скалярных операций в секунду, а GeForce 8800 GTX — только 172,8 млрд. операций в секунду. Однако по результатам первых тестов, несмотря на преимущество в шейдерной производительности, видеокарта на основе R600 проиграла конкуренту от NVIDIA. Многие пользователи, не ориентирующиеся в особенностях архитектуры современных графических процессоров, озадачены одним и тем же вопросом: почему видеокарта, обладающая в 2,5 раза большим количеством шейдерных конвейеров, проигрывает своему конкуренту? Ответом на данный вопрос послужит эта небольшая статья. Архитектура графического процессора NVIDIA G80Cвой новый графический процессор под кодовым названием G80 компания NVIDIA спроектировала на основе принципов скалярной унифицированной шейдерной архитектуры. Что характерно, каждый из его 128-и потоковых скалярных конвейеров (процессоров) может обрабатывать всего лишь по одной операции (команде) за такт. Несмотря на то, что ещё несколько лет назад казалось, что и 20-и конвейеров вполне достаточно, но необходимость в столь большом количестве всё же возникла. Особенность скалярных конвейеров состоит в том, что они могут производить вычисления лишь над одним операндом в некоторый момент времени, а традиционные конвейеры проектируются для одновременной параллельной (векторизированной) обработки 4 операндов. Собственно, архитектура на основе унифицированных (универсальных) шейдерных конвейеров уже сама по себе способствует увеличению реальной производительности графического процессора. При использовании специализированных конвейеров, то есть когда одни предназначены исключительно для обработки вершинных (геометрических) шейдеров, а другие — пиксельных, часто возникают ситуации, когда при расчёте сцены основная нагрузка ложится на пиксельные конвейеры, а вершинные частично простаивают. Или наоборот. Унифицированная архитектура избавлена от этих недостатков, так как каждый шейдерный конвейер может обрабатывать как вершинные, так и пиксельные команды. Блок-схема графического процессора NVIDIA G80 выглядит следующим образом:
Как уже было сказано выше, G80 — это первый графический процессор с поддержкой DirectX 10. Вслед за ним NVIDIA выпустила графические процессоры под кодовыми названиями G86, G84, а также серии G9x и GT200. Все они обладают унифицированной скалярной шейдерной архитектурой. Сравнительная таблица видеокарт GeForce 8 Series:
Сравнительная таблица видеокарт GeForce 9 Series:
Сравнительная таблица видеокарт GeForce 200 Series:
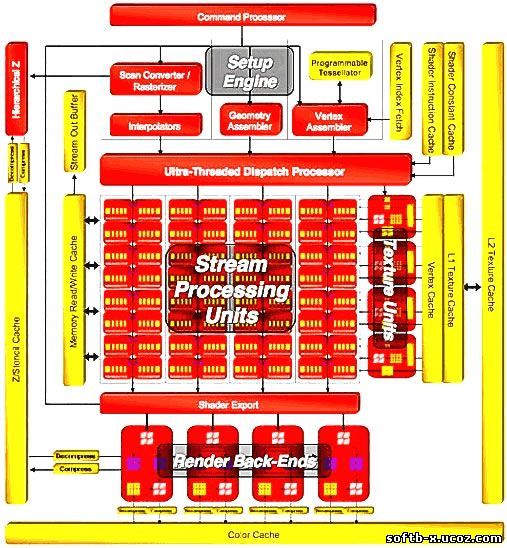
Архитектура графического процессора ATI R600Компания ATI выпустила свой ответ с запозданием примерно на полгода. За это время NVIDIA успела выпустить на рынок несколько видеокарт на основе G80. Как уже было упомянуто, новый продукт под названием Radeon HD 2900 XT основан на графическом процессоре с кодовым названием R600, который обладает 320-ю унифицированными шейдерными конвейерами. Стоит отметить, что нельзя непосредственно сравнивать эти 320 конвейеров R600 со 128-ю конвейерами G80, поскольку отличия в их архитектуре более чем существенны. Об этом и в подробностях. Как и в случае G80, каждый из шейдерных конвейеров R600 может выполнять одну операцию за такт. Дело в том, что конвейеры R600 не являются скалярными в широком смысле этого слова, так как они группируются в блоки по 5 штук. Каждый из этих 64 суперскалярных блоков может выполнять за такт одну скалярную операцию и одну векторизированную на 4-х конвейерах сразу. Теоретически одна такая векторизированная команда эквивалентна 4-м скалярным, но не всегда. Говоря простым языком, 4 одинаковые скалярные операции можно преобразовать в 1 векторизированную. Если же эти 4 скалярные операции отличаются по характеру, то такое преобразование невозможно. Это не имело бы никакого значения, если бы все операции с шейдерами были векторизированными, но на деле всё обстоит иначе, и прямая аналогия между 5-ю конвейерами ATI типа Vec 4+1 и 5-ю скалярными конвейерами NVIDIA просматривается далеко не всегда, поскольку в реальных приложениях доля независимых скалярных расчётов довольно значительна. Очевидно, что это негативно отражается на реальной производительности R600. Какова же теоретическая производительность R600 с 64-ю шейдерными блоками Vec 4+1? Получается, что 47,3 млрд. векторных и столько же скалярных операций в секунду. В таком случае, в зависимости от соотношения количества скалярных и векторных операций в программе, превосходство R600 над G80 с его 43,2 млрд. векторных операций в секунду составит 9-19% при полной векторной нагрузке, а при полностью скалярной примерно двукратное превосходство получит G80. Как показывает практика, в общем случае суперскалярная архитектура R600 не имеет явного преимущества над скалярной архитектурой G80. Блок-схема графического процессора ATI R600:
Суперскалярную архитектуру R600 унаследовали и новые графические процессоры, которые принадлежат к следующим поколениям видеокарт ATI, то есть HD 3xxx и HD 4xxx. Сравнительная характеристика видеокарт HD 2xxx:
Сравнительная характеристика видеокарт HD 3xxx:
Сравнительная характеристика видеокарт HD 4xxx:
ВыводыНесмотря на свою теоретическую шейдерную мощь видеокарты ATI на практике не столь сильны, как может показаться на первый взгляд. В современных играх значительную часть времени занимают скалярные расчёты, что снижает реальную производительность систем на основе видеокарт ATI. С другой стороны, оптимизация шейдерного кода позволяет минимизировать этот недостаток. Примером может послужить сравнение видеокарт GeForce GTX 295 и Radeon HD 4870 X2. Продукт от NVIDIA основан на двух графических процессорах GT200b с 240-ю унифицированными скалярными шейдерными конвейерами каждый, в то время как решение от ATI содержит по 800 конвейеров в каждом из своих двух графических процессоров RV770. Но на самом деле HD4870 X2 имеет только 320 шейдерных блоков (по 160 на графический процессор), производительность которых на скалярных операциях существенно уступает производительности конкурента. Отсюда ответ на вопрос, почему видеокарта с 480-ю шейдерными конвейерами побеждает видеокарту, у которой их 1600, звучит примерно так: видеокарты ATI Radeon обладают суперскалярной архитектурой, в отличие от видеокарт NVIDIA GeForce с их скалярной архитектурой, и реальное количество шейдерных блоков у видеокарт ATI значительно меньше заявленного количества конвейеров. Однако тот факт, что в 3D-приложениях, выпущенных к моменту выхода R600, суперскалярная архитектура не оправдала ожиданий, вовсе не означает, что в ATI неверно выбрали направление и создали ущербную базовую архитектуру. Во время разработки R600 основной акцент был сделан именно на вычисления, а не на скорость текстурирования или скорость заполнения (fill rate) — R600 показывает отличные результаты почти по всех синтетических тестах, особенно в геометрических, а также в тестах сложных пиксельных шейдеров с ветвлениями. Поэтому количество блоков текстурирования и растеризации не столь значительно, как ранее предполагалось. Превосходство R600 в шейдерной производительности будет тем значительнее, чем сложнее (векторизированнее) будут шейдерные операции. ПослесловиеВ данной статье было произведено сравнение архитектуры графических процессоров NVIDIA G80 и ATI R600. Аналогичное сравнение применимо и для последующих поколений видеокарт со скалярной (GeForce 8 / 9 / GTX) и суперскалярной (Radeon HD 2xxx / HD 3xxx / HD 4xxx) архитектурой. Краткий справочник терминов, упоминающихся в статьеШейдер (shader) — это программа для одной из ступеней графического конвейера, используемая в трёхмерной графике для определения окончательных параметров объекта или изображения. Она может включать в себя произвольной сложности описание поглощения и рассеяния света, наложения текстуры, отражение и преломление, затенение, смещение поверхности и эффекты пост-обработки. Пиксельный шейдер (pixel shader) работает с фрагментами изображения, под которыми в данном случае подразумеваются пикселы, обладающие некоторым набором атрибутов, таких как цвет, глубина, текстурные координаты. Пиксельный шейдер используется на последней стадии графического конвейера для формирования фрагмента изображения. Вершинный шейдер (vertex shader) оперирует данными, сопоставленными с вершинами многогранников. К таким данным, в частности, относятся координаты вершины в пространстве, текстурные координаты, тангенс-вектор, вектор бинормали, вектор нормали. Вершинный шейдер может быть использован для видового и перспективного преобразования вершин, генерации текстурных координат, расчета освещения и т. д. Геометрический шейдер (geometry shader), в отличие от вершинного, способен обработать не только одну вершину, но и целый примитив. Это может быть отрезок (две вершины) и треугольник (три вершины), а при наличии информации о смежных вершинах (adjacency) может быть обработано до шести вершин для треугольного примитива. Кроме того, геометрический шейдер способен генерировать примитивы «на лету», не задействуя при этом центральный процессор. Шейдерный конвейер (процессор) — это устройство для обработки одного элемента данных одной командой (типичными элементами данных могут быть целые или числа с плавающей запятой). Блок растеризации (ROP, Raster Operator) — устройство, выполняющее Z-буферизацию, сглаживание и запись обработанного изображения в буфер кадра видеокарты. Блок текстурирования (TMU, Texture Mapping Unit) — устройство, отвечающее за наложение изображений (текстур) на поверхности геометрических объектов.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Просмотров: 1346 | Рейтинг: 0.0/0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Всего комментариев: 0 | |